论文解读 | 2月最新大模型综述——来自Word2Vec作者Tomas Mikolov

介绍

大型语言模型(LLMs)主要指基于Transformer的神经语言模型,这些模型包含数百亿到数千亿个参数,在大规模文本数据上进行预训练,例如PaLM、LLaMA和GPT-4。与PLMs相比,LLMs不仅在模型规模上更大,而且在语言理解和生成能力上表现更强,更重要的是,具有在小规模语言模型中不存在的新兴能力。如上图所示,这些新兴能力包括(1)上下文学习,即LLMs在推理时从提示中呈现的少量示例中学习新任务,(2)遵循指令,即经过指令调整后,LLMs可以遵循新类型任务的指令而无需使用显式示例,以及(3)多步推理,即LLMs可以通过将任务分解为中间推理步骤来解决复杂任务,如链式思维提中所示。LLMs还可以通过使用外部知识和工具进行增强,以便它们可以有效地与用户和环境进行交互,并通过与人类互动收集的反馈数据(例如通过强化学习与人类反馈(RLHF))持续改进自身。
大语言模型

早期预训练神经网络
1999年,Bengio等人开发了最早的神经语言模型(neural language models - NLMs),可与n-gram模型相媲美。此后,基于循环神经网络(recurrent neural networks - RNNs)及其变种,如长短期记忆(long short-term memory - LSTM)和门控循环单元(gated recurrent unit - GRU)的NLMs被广泛用于许多自然语言应用,包括机器翻译、文本生成和文本分类。随后,Transformer架构的发明标志着自然语言模型(NLMs)发展中的又一个里程碑。Transformers比RNNs具有并行的能力,这使得在GPU上可以高效地预训练非常大的语言模型。这些预训练语言模型(pre-trained language models - PLMs)可以针对许多下游任务进行微调。
我们将早期流行的、基于Transformer的PLMs,根据它们的神经架构,分为三个主要类别:encoder-only、decoder-only和encoder-decoder在下文分别介绍。
Encoder-only PLMs:
正如其名,encoder-only models仅包含编码器网络。这些模型最初是为了语言理解任务而开发的,例如文本分类,其中模型需要预测输入文本的类别标签。代表性的为BERT及其变种,例如RoBERTa、ALBERT、DeBERTa、XLM、XLNet、UNILM等。

BERT(Bidirectional Encoder Representations from Transformers)是最广泛使用的encoder-only架构的模型之一。BERT由三个模块组成:(1)一个嵌入模块,将输入文本转换为一系列embedding向量,(2)一堆Transformer编码器,将embedding向量转换为上下文表示向量,以及(3)一个全连接层,将表示向量(在最终层)转换为one-hot向量。BERT经过预训练,使用了两个目标:masked language modeling(MLM)和 next sentence prediction。预训练的BERT模型可以通过添加一个分类器层进行微调,用于许多语言理解任务,从文本分类、问答到语言推理。BERT的整体预训练和微调流程如上图所示。
Decoder-only PLMs
Decoder-only架构的PLMs中,最具代表性的莫过于由OpenAI开发的GPT-1和GPT-2,其出现为GPT-3.5和GPT-4铺平道路。

GPT-1首次证明了通过在未标记文本语料库上,采用自监督学习方式,对Decoder-only架构的生成式预训练(Generative Pre-Training - GPT)模型进行训练,然后通过在每个特定下游任务上进行区分性微调,可以获得在各种自然语言任务上的良好性能。
GPT-2表明,当在由数百万个网页组成的大型WebText 数据集上训练时,语言模型能够学习执行特定的自然语言任务,而无需任何明确的监督。
自监督学习:属于无监督学习的一个子集。在自监督学习中,模型使用未标记的数据集自身作为训练数据。例如,在GPT模型的训练过程中,模型预测下一个Token,而这个预测任务并不需要外部标注的数据,因为下一个Token直接来自于输入数据本身。
Encoder-Decoder PLMs
过去的研究表明,几乎所有自然语言处理任务都可以被视为一个sequence-to-sequence生成任务。因此,Encoder-Decoder语言模型从设计上来说是一个统一的模型,因为它可以执行所有自然语言理解和生成任务。此类别中,最具代表性的莫过于T5、mT5、MASS和BART等。
大模型家族

大型语言模型(Large Language Model - LLMs)主要指包含数十亿到数百亿参数的基于Transformer架构的PLMs。与上述PLMs相比,LLMs不仅在模型大小上更大,而且在语言理解、生成和新兴能力方面表现更强,这些能力在规模较小的模型中不存在。接下来,我们将回顾三个LLM系列:GPT、LLaMA和PaLM:
The GPT Family
生成式预训练(Generative Pre-Training - GPT)是一类基于Decoder-only架构的模型家族,由OpenAI开发。该家族包括GPT-1、GPT-2、GPT-3、InstrucGPT、ChatGPT、GPT-4、CODEX和WebGPT。尽管早期的GPT模型,如GPT-1和GPT-2,是开源的,但最近的模型,如GPT-3和GPT-4,是闭源的,只能通过API访问。
-
GPT-3:一个具有1750亿参数的预训练自回归语言模型。GPT-3被广泛认为是第一个LLM,因为它不仅比以前的PLM大得多,而且首次展示了以前较小的PLM中没有观察到的新兴能力。GPT-3展示了上下文学习的新兴能力,这意味着GPT-3可以应用于任何下游任务,而无需任何梯度更新或微调。
-
CODEX:一种通用编程模型,能够解析自然语言并生成代码作为回答。CODEX是GPT-3的后代,经过在从GitHub收集的代码语料库上进行编程应用的微调。
-
WebGPT:GPT-3的另一个后代,经过微调以使用基于文本的网络浏览器回答开放性问题,帮助用户搜索和浏览网络。
-
InstructGPT:为了使LLMs能够遵循人类指令,InstructGPT被提出,通过使用人类反馈(RLHF)进行微调,使其与用户意图在各种任务上保持一致。

RLHF的概述RLHF:从一组由标注者编写的提示和通过OpenAI API提交的提示开始,收集了一组标注者演示所需模型行为的数据集。然后在这个数据集上对GPT-3进行微调。接着,收集了一组人类排名的模型输出数据集,通过强化学习进一步微调模型。该方法被称为从人类反馈中学习强化学习(RLHF)。
-
ChatGPT(GPT-3.5):LLM发展中最重要的里程碑是于2022年11月30日推出的ChatGPT。ChatGPT是一款聊天机器人,使用户能够引导对话以完成各种任务,如回答问题、寻找信息、文本摘要等。ChatGPT由GPT-3.5驱动,是InstructGPT的姊妹模型。

- GPT4:GPT系列中最新、最强大的LLM。于2023年3月推出,GPT-4是一种多模态LLM,可以接受图像和文本作为输入,并生成文本输出。虽然在一些最具挑战性的现实场景中仍不及人类,但GPT-4在各种专业和学术基准测试中表现出人类水平的性能,包括通过模拟的律师资格考试,得分约为前10%的考生,如上图所示。与早期的GPT模型一样,GPT-4首先经过预训练,以预测大型文本语料库中的下一个标记,然后通过RLHF进行微调,以使模型行为与人类期望的行为一致。
The LLaMA Family
LLaMA是由Meta发布的一系列大语言模型。与GPT模型不同,LLaMA模型是开源的。
- LLaMA-1:第一批LLaMA模型于2023年2月发布,参数范围从7B到65B。这些模型在从公开可用数据集中收集的数万亿个Token上进行了预训练。LLaMA使用了GPT-3的Transformer架构,进行了一些轻微的架构修改。
- LLaMA-2:2023年7月,Meta与微软合作发布了LLaMA-2系列,其中包括基础语言模型和针对对话进行微调的Chat模型,称为LLaMA-2 Chat。
The PaLM Family
PaLM(Pathways Language Model)系列由Google开发。
- 首个PaLM模型于2022年4月宣布,其在6144个TPUv4芯片上使用Pathways系统进行预训练,包含5400亿参数,于2023年3月开源。
- PaLM-2与其前身PaLM相比,使用混合目标进行训练。通过对英语、多语言和推理任务的广泛评估,PaLM-2在不同模型大小下显著提高了在下游任务上的模型性能,同时展现出比PaLM更快速和更高效的推理能力。
其他
-
Mistral-7B:一个专为卓越性能和效率而设计的7B参数语言模型。Mistral-7B在所有评估基准中均优于LLaMA-2-13B,并在推理、数学和代码生成方面优于LLaMA-34B。该模型利用分组查询注意力以实现更快的推理,结合滑动窗口注意力有效处理任意长度的序列,并降低推理成本。

BLOOM架构 -
BLOOM:Scao等人提出了BLOOM,这是一个拥有176B参数的开放获取语言模型,是由数百名研究人员合作设计和构建的。BLOOM是一个仅解码器的Transformer语言模型,是在ROOTS语料库上训练的,该语料库包含46种自然语言和13种编程语言的数百个来源(共59种)。其架构如上图所示。
-
GLM:一个大型双语(英语和中文)预训练语言模型,具有1300亿个参数。它旨在公开一个与GPT-3(davinci)至少同等水平的1000亿级别的模型。
-
Gemini:Gemini团队介绍了一系列新的多模态模型,支持32k上下文长度。Gemini系列包括三个版本:Ultra用于高度复杂的任务,Pro用于增强性能和规模部署能力,Nano用于设备应用。
如何构建一个大模型
架构选择
如上文所述,目前最广泛使用的LLM架构包括encoder-only、decoder-only和encoder-decoder架构。
在此,我们首先回顾Transformer架构。其最初在论文《Attention is all you need》中被提出,最初是为了利用GPU进行有效的并行计算而设计的。其核心是注意力机制,相比于循环和卷积机制,注意力机制可以(1)更有效地利用GPU和(2)捕捉长期上下文信息。其中,注意力函数可以描述为将query和一组key-value对映射到输出,其中query、key、value和输出都是向量。输出是value的加权和,其中分配给每个值的权重由query与相应key的兼容性函数计算。
Encoder-Only
对于Encoder-Only架构,在每个阶段,注意力层可以访问初始句子中的所有单词。这些模型的预训练通常包括以某种方式破坏给定句子(如mask)并要求重构句子。Encoder-Only架构非常适用于需要理解完整序列的任务,如句子分类、命名实体识别和抽取式问答。
Decoder-Only
对于Decoder-Only架构,在每个阶段,对于任何Token,注意其前面的Token。这些模型有时也被称为自回归模型。这些模型的预训练通常被制定为预测序列中的下一个Token(Next token prediction)。Decoder-Only架构适合涉及文本生成的任务。GPT模型是这一模型类别的杰出示例。
Encoder-Decoder
Encoder-Decoder架构同时使用编码器和解码器,有时被称为sequence-to-sequence模型。在每个阶段,Encoder的注意力层可以访问初始句子中的所有单词,而Decoder的注意力层只能访问输入中给定Token之前的Token。Encoder-Decoder模型适合,给定的输入比如摘要、翻译或生成式问答,生成新句子的任务。
数据清洗
数据质量对于在其上训练的语言模型的性能至关重要。诸如过滤、去重等数据清洗技术已被证明对模型性能有重大影响。
数据过滤
数据过滤旨在提高训练数据的质量和训练后LLM的效果。常见的数据过滤技术包括:
- 数据去噪:如删除虚假信息
- 处理异常值
- 类别不平衡:平衡数据集中类别的分布
- 文本预处理:去除停用词、标点符号等
- 处理歧义:处理模糊或矛盾数据
数据去重
去重指删除重复实例或重复出现的相同数据。重复数据点可能会在模型训练过程中引入偏见并降低多样性。一些研究表明,去重可以提高模型对新的、未见数据的泛化能力。
分词
Tokenization是将文本序列转换为较小部分即Token的过程。
模型预训练
预训练是大型语言模型训练流程中的第一步。在预训练期间,LLM通常以自监督的方式在大量(通常是)未标记的文本上进行训练。 用于预训练的不同方法最常见的两种是next token prediction 和 masked language modeling,MLM。
- next token prediction:从左到右(或从右到左)逐Token预测句子中的下一个Token,建立Token与Token之间的依赖关系。适合于文本生成任务,如机器翻译、文本生成等。
- masked language modeling:在MLM中,模型通过预测句子中随机掩盖的单词来学习Token之间的关系,训练模型理解单词的上下文含义。MLM更适合于理解任务,如文本分类、命名实体识别等。
微调(Fine-tuning)和指令微调(Instruction Tuning)
-
微调通常有两个目的:(1)使基座模型应对不同的任务,(2)增加新的知识
-
除了微调,我们还希望大模型理解和遵循人类的自然语言指令。此时就需要指令微调。
对齐
AI对齐(AI Alignment)是将AI系统引导朝向人类目标、偏好和原则的过程。有时,大型语言模型为了进行Token预测会表现出危险行为。比如,它们可能生成不良、有害、误导性和偏见的内容。
在此阶段,两种流行的方法是RLHF(来自人类反馈的强化学习)和RLAIF(来自AI反馈的强化学习)。
- RLHF:RLHF使用奖励模型从人类反馈中学习对齐。调整后的奖励模型能够评估不同的输出,根据人类给定的对齐偏好对要训练的模型的输出进行评分。
- RLAIF:另一方面,RLAIF直接将一个预训练且对齐良好的模型连接到要训练的LLM,并帮助其从这个更大、更对齐的模型中学习。这种方式类似于一种广义的知识蒸馏。
解码策略
解码是指使用预训练的大型语言模型生成文本的过程。给定一个输入Prompt,分词器将输入文本中的每个Token转换为相应的Token的数值表示。然后,语言模型使用这些Token的数值表示作为输入,并预测下一个最有可能的Token。最后,模型生成logits,通过softmax函数将其转换为概率。已经提出了不同的解码策略。其中一些最流行的策略包括贪心搜索,束搜索,top-K,top-P等。
Greedy Search
贪婪搜索在每一步中选择最有可能的标记作为序列中的下一个标记,丢弃所有其他潜在选项。正如许多贪心算法的缺陷一样,这种方法可能会丧失文本的一致性和连贯性。它只考虑每一步中最有可能的Token,而不考虑生成的序列整体效果。
Beam Search
与贪婪搜索只考虑下一个最可能的标记不同,束搜索考虑了N个最可能的Token,其中N表示束的数量。该过程重复进行,直到达到预定义的最大序列长度或出现序列结束标记。此时,具有最高总体分数的Tokne序列(也称为“束”)被选择为输出。例如,对于束大小为2且最大长度为5,束搜索需要递归生成并评估$2^5 = 32$个可能的序列。因此,它比贪婪搜索需要更大的计算量。
Top-k
Top-k抽样利用语言模型生成的概率分布从k个最有可能的选项中随机选择一个Token。
假设我们有6个Token(A,B,C,D,E,F),设k=2,P(A)=30%,P(B)=20%,P(C)=P(D)=P(E)=P(F)=12.5%。在top-k抽样中,Token C、D、E、F被忽略,模型输出A的概率为60%,输出B的概率为40%。这种方法确保我们优先考虑最有可能的Token,同时引入一定的随机性。
在该方法中,我们通常通过温度的概念引入随机性。温度T是一个从0到1的参数,影响softmax函数生成的概率,其作用如公式所示: $$ softmax(x_i)=\frac{e^{x_i/T}}{\sum_je^{x_j/T}} $$ 如公式所示,当温度较低时,概率分布会变得更加尖锐,这意味着概率较高的tokens会变得更加显著,从而使生成的文本更加确定,减少创造性;而高温度会使得概率分布更加平坦,赋予低概率tokens更多的机会,从而增加文本的多样性和创造性。
Top-p
Top-p抽样,也被称为核抽样(Nucleus sampling),与top-k抽样有略微不同的方法。与选择前k个最可能的Token不同,核抽样选择一个阈值p,使得所选Token的概率之和超过p。换言之,在top-p抽样中,模型按降序检查最可能的Token,并将它们逐个添加到列表中,直到概率之和超过阈值p。
利用大模型
大模型的限制
- 没有状态/记忆:它们本身甚至无法记住之前提示中发送给它们的内容
- 回答是随机的/概率性的:如果多次向大模型发送相同输入,很可能会得到不同的回复
- 过时的信息
- 训练成本高
- 幻觉
这里只对即大模型幻觉(Hallucinations)进行探讨。
LLM中的幻觉被描述为"生成的内容是荒谬的或不忠实于提供的来源",其可被分为两种类别:
- 内在幻觉(Intrinsic Hallucinations):幻觉与原始材料直接冲突,事实不准确或逻辑不一致。
- 外在幻觉(Extrinsic Hallucinations):无法从来源进行验证,包含了推测性或不可证实的元素。
幻觉的影响高度依赖于上下文和任务。例如,在像写诗这样的创造性努力中,幻觉可能被认为是可以接受甚至有益的。
最近对于大模型幻觉的工作,如指导微调和来自人类反馈的强化学习(RLHF),试图引导LLM生成更加基于事实的输出,但其固有的概率性质和局限性仍然存在。
Prompt工程
在于LLM打交道的过程中,Prompt是用户提供的文本输入,用于引导模型的输出。Prompt通常包括指令、问题、输入数据和示例。
典型的Prompt有:
- Chain of Thought (CoT):大名顶顶的CoT,让大模型Think step by step从而获得更好的输出。其包含两种主要形式:
- Zero-shot CoT:在问题后面加上"Let’s think step by step"。
- Manual CoT:需要人为模型提供逐步推理示例作为模板。
- 上述两种方法中,Manual CoT比Zero-shot CoT更有效。然而,通过手动构建CoT是困难且容易出错的。而Auto CoT就不具备这个问题,详情见Auto CoT——利用聚类自动生成CoT。
- Tree of Thought(ToT):基于CoT的思想,ToT可以展开形成多个"思维树",其中每个分支代表不同的推理线路即CoT。
- Self-Consistency:在给定Prompt的下,LLM不只生成一个回答,而是生成多个回答。之后对这些候选回答进行评估,以确定它们之间的一致性。最后,选择在所有回答上保持一致性最好的回答作为最终输出。
- Reflection:促使大模型根据对其回答的正确性和连贯性的推理来评估并可能修改其输出。
- Expert Prompting:提示LLMs扮演专家角色并相应地回答问题,提供高质量、知情的答案。
RAG
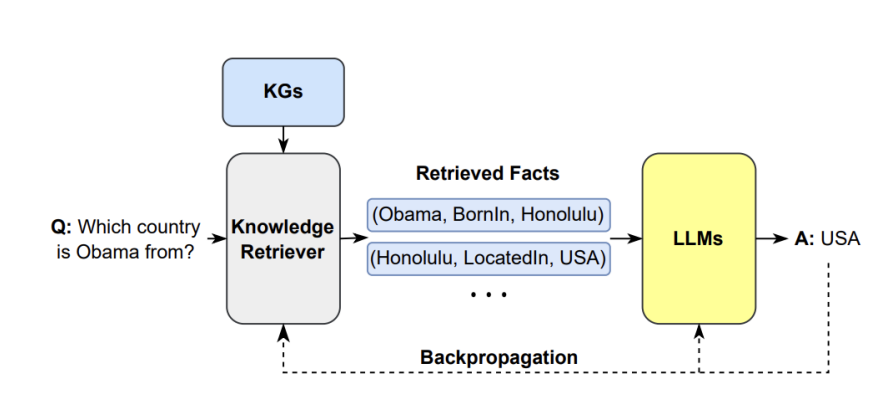
如上图所示所示,RAG从Prompt中提取查询的问题,并使用该查询的问题从外部知识源(例如搜索引擎或知识图谱)检索相关信息。然后将相关信息添加到Prompt中,并将其馈送给大模型,使得大模型生成最终回答。
大模型Agents

AI Agents的概念有着深远的历史。AI Agents通常是一个自主实体,可以利用其传感器感知环境,根据当前状态做出判断,并行动。
在大模型的背景下,Agents指的是基于大模型能够自主执行特定任务的系统。这些Agents被设计用于与用户或环境进行交互,根据输入和交互的预期目标做出决策。Agents的核心特点是:
- 能够访问和使用工具
- 能够自主决策
在此领域比较有代表性的工作是ReAct,LATS等,感兴趣的读者可以阅读笔者之前的文章ReAct——LLM推理范式 推理+动作。
数据集

挑战
更小更高效的模型
当前的研究趋势是提出小型语言模型(SLMs)作为对LLMs的更经济的替代选项,特别是在不需要如此大模型的任务时。
注意力机制之后引入的新的架构范式
这类在注意力模型后被提出的模型中的一个重要类别是状态空间模型(SSMs)。虽然状态空间模型的概念在机器学习中有着悠久的历史,但在语言模型的背景下,SSM通常是指较新的结构状态空间模型架构,简称S4。这一类别中的一些最近模型包括Mamba、Hyena和Striped Hyena。
另一方面,最近一些与注意力兼容的架构机制正在逐渐崭露头角,如专家混合(MoE)。值得注意的是,MoEs可以作为任何架构的组成部分,无论其是否基于注意力机制。
多模态
目前已经有几个知名的多模态LLMs存在,包括:LLAVA(视觉语言模型)、LLAVA-Plus(LLAVA的扩展版)、GPT-4、Qwen-vl、 Next-GPT等。
大模型的使用和增强技术
如Prompt和RAG等
大模型安全
如隐私、偏见等。