论文解读 | Reasoning with Language Model is Planning with World Model

Title: Reasoning with Language Model is Planning with World Model
Institute: UCSan Diego, University of Florida
Authors: Shibo Hao Yi Gu Haodi Ma Joshua Jiahua Hong Zhen Wang Daisy Zhe Wang Zhiting Hu
Link: https://arxiv.org/pdf/2305.14992.pdf
Shared Link: https://mp.weixin.qq.com/s/ZLktf__PCPsMYdX-Ikm_5A
简介
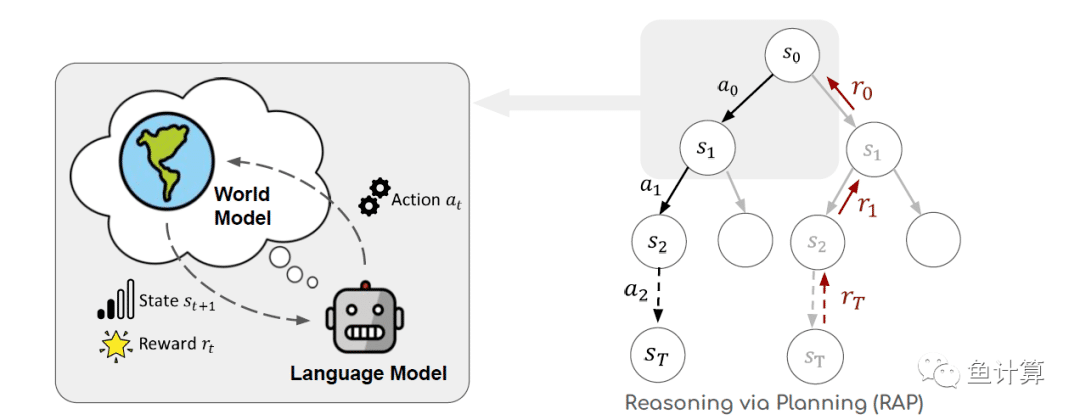
过去的研究证明,人类拥有一个内部的世界模型,使人类能够模拟行动及其对世界状态的影响,以进行复杂任务的有意识的规划,包括运动控制、想象、推理和决策。而大模型只能通过自回归的方式进行推理,作者认为限制大模型的推理的原因主要有三个:
-
缺少内部模型对当前状态的模拟
-
缺少奖励机制来指导模型推理
-
无法在对未来的探索和对过去经验的汲取间达到平衡
对于第一个问题,作者将强化学习概念引入reasoning提出使用llm作为world model实现对当前状态的模拟
对于第二个问题,作者基于大模型设计了四种奖励方式
对于第三个问题,作者使用蒙特卡洛树搜索解决
世界模型
此处的世界模型是强化学习中的概念,可以理解为外界环境、对行动的模拟、行为的结果等概念。在这里作者使用prompting + llm实现世界模型。
令当前状态为 $s_{t,t=0,1,2,3...T}$。大模型作为agent通过 $s_t$ 和prompt $ c$ 推理出行动 $a_t$ 的过程可以被描述为 $a_t \sim p(a|s_t,c)$ 。此时作为世界模型的llm根据 $ a_t$ 和 $s_t$ 预测出下一个时刻的状态 $s_{t+1}$。
奖励
在推理步骤中,需要考量每一次推理的可行性用于指导推理。设计评估函数 $r_t=r(s_t,a_t)\in\mathbb{R}$,根据t时刻的状态$s_t$和动作$a_t$来获得回报。
基于蒙特卡洛树搜索的推理过程
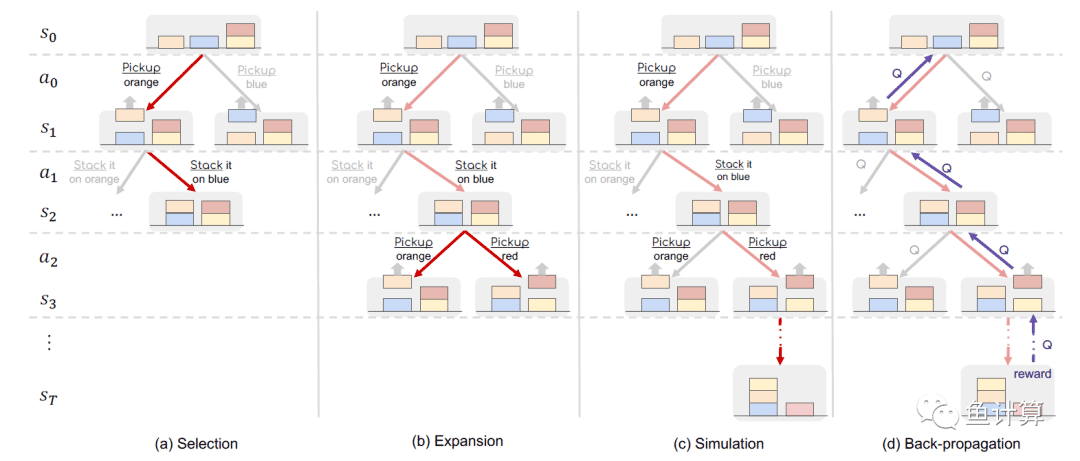
蒙特卡洛树搜索主要可分为如下四个步骤
-
Selection: 在Selection阶段根据UCB值选取期望回报最高的叶子节点
-
Expansion: 在Expansion阶段对该叶子节点进行拓展
-
Simulation: 对拓展的叶子节点进行仿真,判断结果
-
Back-propagation: 反向传播
重点介绍Selection和Simulation阶段
Selection:
对于候选节点,根据UCB公式计算每个节点的UCB值
$a^*=\arg\max\limits_{a\in A(s)}\left[Q(s,a)+w\sqrt{\frac{\ln N(s)}{N(c(s,a))}}\right]$-
作为第一项的Q值表示此节点在过去时间的平均奖赏,是对过去经验的汲取。
-
第二项中的 $N$是访问次数, $c(s,a)$是此节点(将$a$动作施加于$s$状态)的子节,是对未来的探索。
-
$w$是第二项的权重
根据此公式可知,Selection策略具有如下特点
-
向于选择过去获得回报更高的节点
-
倾向于选择未被探索的节点
这样,通过蒙特拉洛树搜索中的UCB公式就可以解决exploration vs. exploitation难题。
Simulation
这个阶段使用世界模型来模拟当前节点的未来情况。从上面的当前节点开始,在每个节点 $s_t$处,我们按照一个扩展策略创建一个动作 $a_t$,并使用世界模型预测下一个状态 $a_{t+1}$。扩展过程会一直进行,直到达到一个终止状态。
如上图$(c)$