论文解读 | ReAct——LLM推理范式 推理+动作

titile: REACT: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS
institute: Department of Computer Science, Princeton University
author: Shunyu Yao,Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, Yuan Cao
Link: https://arxiv.org/pdf/2210.03629.pdf
Shared Link: https://mp.weixin.qq.com/s/5DFnutIpNIPRyJ7EUlfiEw
动机
-
CoT方法是黑盒推理,推理过程和知识局限于模型内部
-
前人有工作探索了在互动环境中使用预训练语言模型进行规划和行动
启发
人类在两个行动之间会通过语言来追踪进展,例如“现在所有的食材都切好了,我应该烧水了”。作者从人类的这个现象中获得启发,希望能够将大模型的推理过程显式表达出来。
ReAct

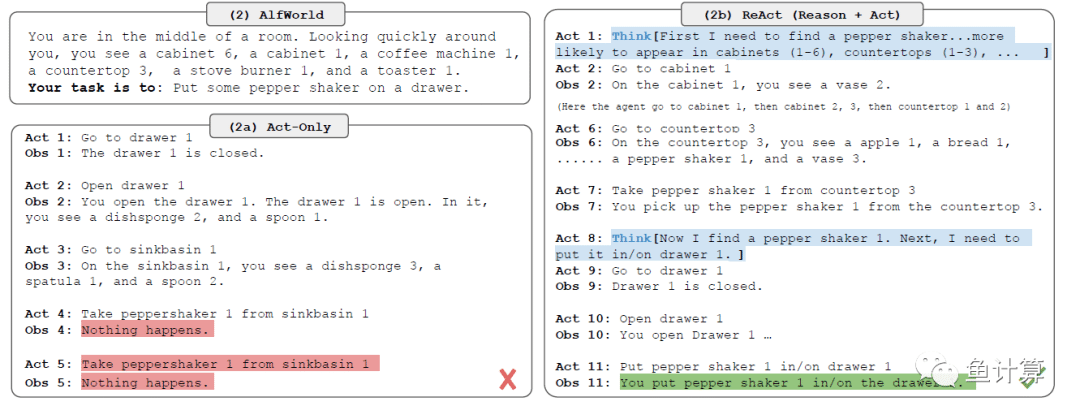
ReAct是一套针对大模型能够将thought和Act结合起来的框架。
在$t$时刻,设观察到的信息为$o_t\in\mathcal{O}$,Act为$a_t\in\mathcal{A}$,其中$a_t$遵循策略$\pi(a_t|c_t)$,$c_t=\left(o_1,a_1,\cdots,o_{t-1},a_{t-1},o_t\right)$。然而直接$c_t\mapsto a_t$这个过程是隐式的且需要大量计算的。
而ReAct的方法很简单就是扩充$\mathcal{A}$集为$\hat{\mathcal{A}}=\mathcal{A}\cup\mathcal{L}$。而$\mathcal{L}$集就是思考或推理过程。此时$\hat a_t\in\mathcal{L}$就是根据上下文$c_t$获得的Act。在下一轮中$c_{t+1}=\left(c_{t},\hat{a}_{t}\right)$作为上下文供生成Act。
ReAct的每一个过程都是行动、思考、环境观察。
然而这个过程存在缺点,那么就是模型容量必须足够大,具体而言,本文中使用的就是540B的模型。
作者将任务话分成两类分别是推理主导任务和决策主导任务。
-
推理主导:对于推理很重要的任务,作者使用思考-行动-观察流程。例如多推理的任务。
-
决策主导:相反,对于涉及大量操作的决策任务,思考只需要偶尔出现就可以了。例如,你在一个厨房里,环境是xxx,你需要找xxx。