论文解读 | 思维链越长大模型越聪明?
Title: The Impact of Reasoning Step Length on Large Language Models
Institute: Northwestern University, University of Liverpool, New Jersey Institute of Technology, Rutgers University
Authors: Mingyu Jin, Qinkai Yu, Dong Shu, Haiyan Zhao, Wenyue Hua, Yanda Meng, Yongfeng Zhang, Mengnan Du
Arxiv Link: https://arxiv.org/abs/2401.04925
Date: 2024.1.20
介绍
思维链(Chain of thought - CoT)在过去的实践中已经证明对提升大模型的推理能力有显著帮助。然而,目前还没有一项工作解释思维链长度与推理能力之间的关系。本文围绕这一核心问题,围绕CoT做了系统实验,并给出许多有意思和反直觉的结论。
结论
闲言少叙,直接上结论
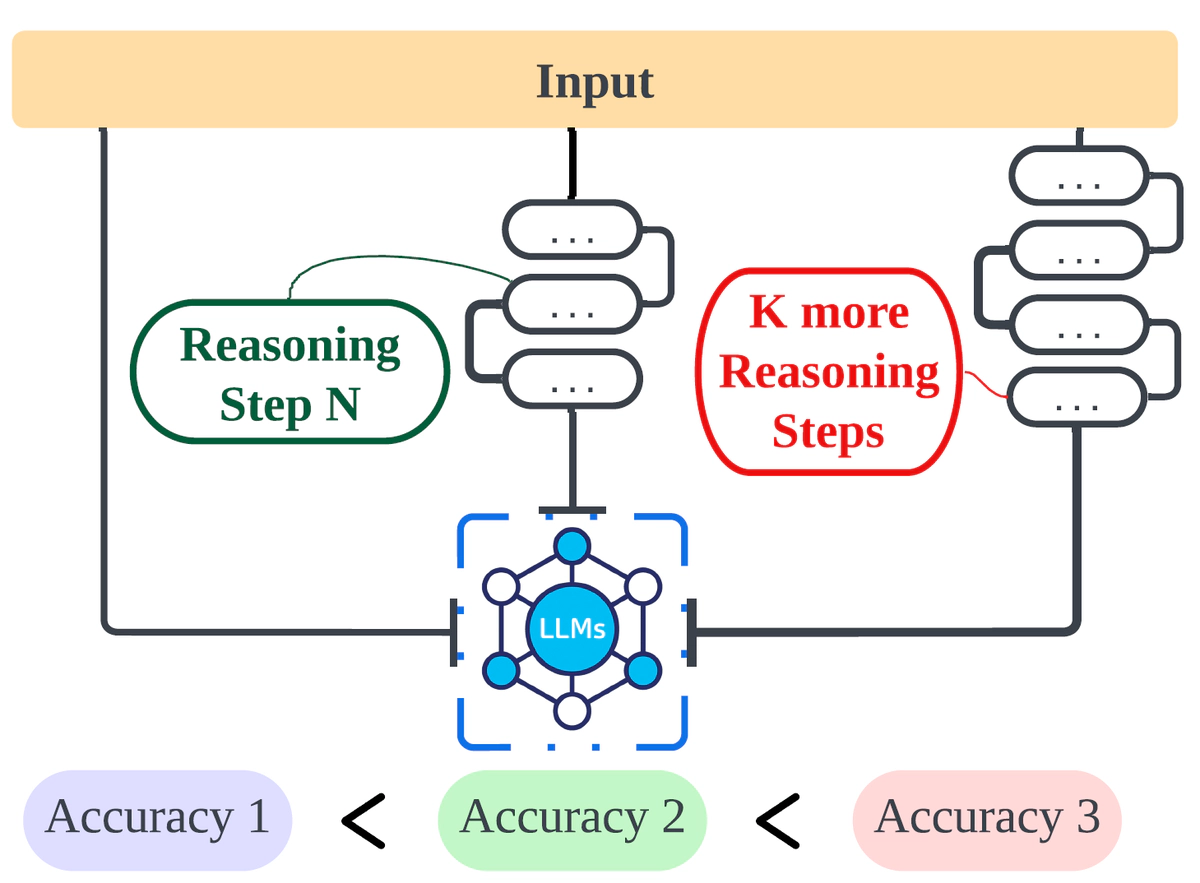
- 对于Few-shot CoT,模型回答的准确率与推理的步数呈线性关系。步数越长,模型回答越准确。相反,减少CoT长度,即使保证链条里的关键信息与长链条相同,也会显著降低模型的准确率。
- 即使CoT链条中存在不正确的推理,如果保持必要的推理长度,也会产生有利的结果。也就是说,只要链条更长,即使中间步骤推错了,也会提高准确率。
- 简单任务需要的步数少,复杂任务需要的步数多。
- 即使是Zero-shot CoT,加了一句"你必须使用更多的步骤"相比于只有"让我们来一步一步思考"也会提高大模型的性能。
实验设置
Zero-shot CoT
文中的Zero-shot CoT默认设置为"Let’s think step by step",作者在本文探究其与"Let’s think step by step, you must think more steps"对llm的影响。
Few-shot CoT

如上图所示,在本文的Few-shot Cot被设置为了如下的几个步骤:
- Think About The Word: 作者首先让LLM思考问题中单词的意义(想好每个词啥意思再回答)。比如说对于问题"Could someone in Tokyo take a taxi to the Metropolitan Museum of Art?",如下图所示,作者会让LLM先想一想"Tokyo", “taking a taxi”, “Metropolitan Museum of Art” 都是什么意思——“Think about Tokyo… Think about taking a taxi… Think about Metropolitan Museum of Art…"。

-
Read the question again:让LLM重读一遍问题(再审一遍题)
-
Repeat State:让LLM对问题形成一个摘要,简化记忆,减少CoT中的其他单词的影响(提取问题中的关键信息)
-
Self-Verificatio:增加了一个自我验证过程,根据一些基本信息来判断答案是否合理。(先自己想一下你的回答对不对)
-
Make Equation:对于数学问题,让LLM对问题进行建模
实验及结论
步数与准确率的关系

如上图所示,每张子图的x轴为CoT链条的长度(推理步数),y轴为LLM的准确率。显然,CoT链条越长,准确率越高。这一发现横跨所有的数据集和任务。
CoT中一个环节推错了,会发生什么?
对于CoT的研究者而言,最重要的研究莫过于如何让CoT的每一步都推对,从而接近正确的答案。在这一章节,作者提出问题,如果CoT中某一链推错了,对LLM推出结果会产生什么影响呢?

如下图所示,x轴表示8类任务/数据集,两个颜色的柱状图分别表示全对的链条和包含错误回答的链条。作者发现:
- 对于数学问题,某一环节错了,影响很小。作者认为llm学习的是计算模式而不是计算的结果本身,因此不受影响。例子如下图所示,本图中,右侧的错误prompt将
10+8的结果计算为了错误的48。 - 对于逻辑问题,错一点会导致思维链破裂,影响很大。

压缩推理步骤,会发生什么?
这里的压缩推理步骤指的是在每个步骤,用更简短的语言来提问。结果表明压缩推理步骤导致其性能接近Zero-shot,进一步说明推理步骤和LLM的准确率重要关联。
模型的参数量对结果的影响
如下图,显而易见,参数量越大越准确。

不同的CoT生成方法区别大吗?
由于本文主要研究推理步骤对性能的影响,因此需要确认CoT中问题本身对LLM的性能没有影响。
因此,本文在LLM为GPT-3.5-turbo-1106的设置下,选择了两个数据集(MultiArith和GSM8K)和两种CoT方法(Auto CoT和Few-shot CoT)进行这项研究。
如下图所示,初步观察表明,这些修改对性能的影响微乎其微。 这一初步发现表明,在推理过程中,步骤的长度,而不是问题本身的性质,主要影响大型模型的推理能力。

评价
本文虽然难度不大,但是对CoT的评测却很全面,角度很新奇,也发现了很多有意思的结论。