论文解读 | 面向LLM的图结构多模态表示
Title: Which Modality should I use – Text, Motif, or Image? : Understanding Graphs with Large Language Models
Institution: Minnesota NLP, University of Minnesota
Authors: Debarati Das, Ishaan Gupta, Jaideep Srivastava, Dongyeop Kang
Arxiv Link: https://arxiv.org/abs/2311.09862
Code Link: None
Date: 2023.11.16
Abstract: Large language models (LLMs) are revolutionizing various fields by leveraging large text corpora for context-aware intelligence. Due to the context size, however, encoding an entire graph with LLMs is fundamentally limited. This paper explores how to better integrate graph data with LLMs and presents a novel approach using various encoding modalities (e.g., text, image, and motif) and approximation of global connectivity of a graph using different prompting methods to enhance LLMs’ effectiveness in handling complex graph structures. The study also introduces GraphTMI, a new benchmark for evaluating LLMs in graph structure analysis, focusing on factors such as homophily, motif presence, and graph difficulty. Key findings reveal that image modality, supported by advanced vision-language models like GPT-4V, is more effective than text in managing token limits while retaining critical information. The research also examines the influence of different factors on each encoding modality’s performance. This study highlights the current limitations and charts future directions for LLMs in graph understanding and reasoning tasks.
Introduction:
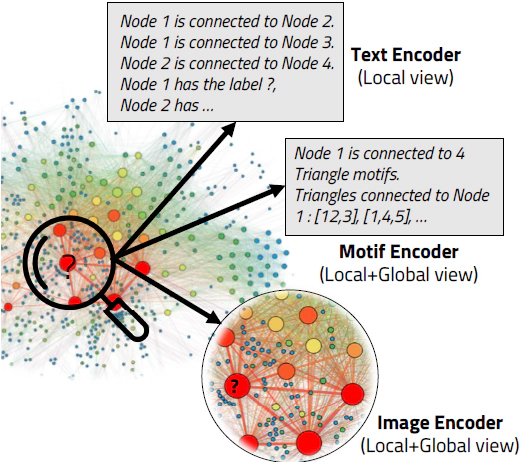
In this paper, we explore the impact of encoding global and local graph structures using different modalities, particularly focusing on node classification tasks.
In specific, this paper compare three modalities: Text, Motif, and Image.
The reason why this paper introduce MOTIFS :
However, it becomes too verbose for large graphs, potentially exceeding the input context limits of large language models like GPT-4 . To circumvent this, we suggest Motif modality encoding, which captures essential patterns within the node’s vicinity, offering a balanced local and global perspective.
Methodology
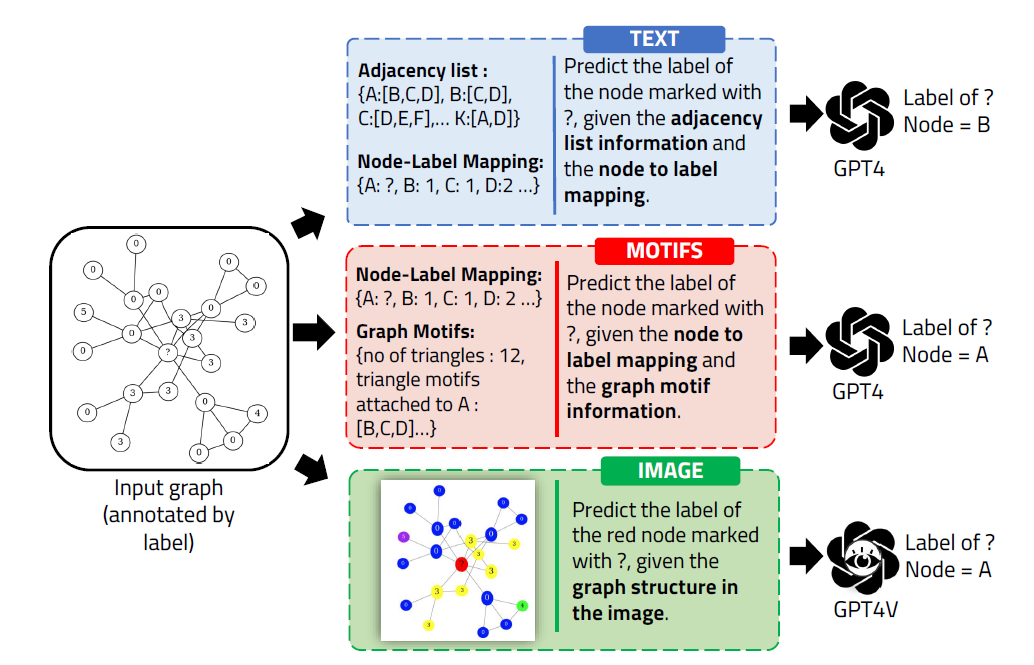
Text Encoder Modality
Encoding graphs as text can be separated into two key parts:
- the mapping of nodes to their corresponding labels in the graph
- {node ID: node label}
- the encoding of edges between the nodes
We consider the importance of some factors that can influence the performance of text modality encoding :
- Edge Encoding Function
- Graph Structure
- Sampling Strategy
Edge Encoding Function
- Edgelist
- Edgetext
- Adjacency List
- GML
- GraphML
Edgelist:
Node to Label Mapping : Node 69025: Label 34| Node 17585: Label 10|...
Edge list: [(69025, 96211), (69025, 17585), (17585, 104598), (17585, 18844), (17585, 96211), (96211, 34515)]
Edgetext:
Node to Label Mapping : Node 85328: Label 16| Node 158122: Label ?|...
Edge connections (source node - target node): Node 85328 is connected to Node 158122. Node 158122 is connected to Node 167226.
Adjacency List:
Node to Label Mapping : Node 2339: Label 3| Node 2340: Label ?|...
Adjacency list: 1558: [2339, 2340], 2339: [1558, 2340], 2340: [2339,1558]
GML:
A GraphML format consists of an unordered sequence of node and edge elements enclosed within [].
The node label information is embedded within the structure, meaning no node-label mapping is notneeded.
GraphML:graph [
node [
id 2339
label 3
]
node [
id 2340
label ?
]
node [
id 1558
label 3
]
edge [
source 2339
target 1558
]
edge [
source 2339
target 2340
]
]
GraphML:
A GraphML file consists of an XML file containing a graph element, within which is an unordered sequence of node and edge elements.
GraphML:<graphml xmlns=http://graphml.graphdrawing.org/xmlns
xmlns:xsi=http://www.w3.org/2001/XMLSchema-instance
xsi:schemaLocation=http://graphml.graphdrawing.org/xmlns
http://graphml.graphdrawing.org/xmlns/1.0/graphml.xsd>
<graph edgedefault=undirected>
<node id=2339 label=3 />
<node id=2340 label=? />
<node id=1558 label=3 />
<edge source=2339 target=1558 />
<edge source=2339 target=2340 />
</graph>
</graphml>
Graph Structure
We selected real-world citation datasets with differing network properties to explore the significance of graph structure on node classification.
- CORA
- Citeseer
- Pubmed
Sampling Strategy
- Ego graph
- Forest Fire sampling
Example :
Task: Node Label Prediction (Predict the label of the node marked with a ?) given the adjacency list information as a dictionary of type “node: neighborhood” and node-label mapping in the text enclosed in triple backticks. Response should be in the format “Label of Node = <predicted label>”.
If the predicted label cannot be determined, return “Label of Node = -1”.
```AdjList: {1: [2,3], 2: [3,4], 3: [1,2]}
Node-Label Mapping: {1: A, 2: B, 3: ?} ```
Motif Modality
Encoding graphs as motifs can be separated into two key parts:
- the encoding of nodes to their corresponding labels in the graph
- the motifs present around the ? (unlabeled) node.
Motif information
| Type of Motif | Motif Encoding | Description of Motif |
|---|---|---|
| Node-Label Mapping | Node to Label Mapping : Node 1889: Label 4 | … Node 1893: Label 2|… | Only the node-label mapping is provided (this gives no connectivity information to LLM) |
| No. of Star Motifs | Node to Label Mapping : Node 1889: Label 4 | … Node 1893: Label 2|… Graph motif information: Number of star motifs: 0| | Star motifs signify centralized networks with influential central nodes, where a central node is connected to others that aren’t interlinked. We pass the count of the star motifs present in the graph. |
| No. of Triangle Motifs | Node to Label Mapping : Node 1889: Label 4 | … Node 1893: Label 2|… Graph motif information: Number of triangle motifs: 6| | Triangle motifs (triads connecting three nodes) are foundational in social networks, indicating transitive relationships, community structures, and strong social ties. We pass the count of the triads present in the graph. |
| No. of Triangle Motifs Attached | Node to Label Mapping : Node 1889: Label 4 | … Node 1893: Label 2|… Graph motif information: Triangle motifs attached to ? node: |1893,2034,1531|, |1893,1531,429| | We pass the triangle motifs attached to the ? label, which gives an idea of the influential triads connected to the ? node. |
| No. of Star Motifs Attached | Node to Label Mapping : Node 1889: Label 4 | … Node 1893: Label 2|… Graph motif information: Star motifs connected to ? node: | | | We pass the star motifs attached to the ? label, which gives an idea of the influential nodes connected to the ? node. |
| No. of Star and Triangle Motifs | Node to Label Mapping : Node 1889: Label 4 | … Node 1893: Label 2|… Graph motif information: Number of star motifs: 0| Number of triangle motifs: 6| | We pass the count of the triads and star motifs present in the graph, to give the LLM an idea of the graph structure. |
| Star and Triangle Motifs attached | Node to Label Mapping : Node 1889: Label 4 | … Node 1893: Label 2|… Graph motif information: Triangle motifs attached to ? node: |1893,2034,1531|, |1893,1531,429| Star motifs connected to ? node: | | | We pass the star motifs and triads attached to the ? label, which gives an idea of the influential nodes and triads connected to the ? node. |
| No of cliques ? Node is part of | Node to Label Mapping : Node 1889: Label 4 | … Node 1893: Label 2|… Graph motif information: Number of cliques in graph: 0| Node is a part of these cliques: | | | We pass the number of cliques in the network, which gives an idea of its clustered nature. We also pass the cliques the ? label is a part of, which gives an idea of the immediate community of the unlabelled node. |
| No of cliques ? Node is attached to | Node to Label Mapping : Node 1889: Label 4 | … Node 1893: Label 2|… Graph motif information: ? Node is attached to these cliques: | | | We pass the cliques the ? label is attached to, which gives an idea of the neighboring influential community of the unlabelled node. |
Example
Task: Node Label Prediction (Predict the label of the node marked with a ?) given the node-label mapping and graph
motif information in the text enclosed in triple backticks. Response should be in the format “Label of Node = <predicted
label>”.
If the predicted label cannot be determined, return “Label of Node = -1”.
```Node-Label Mapping: {1: A, 2: A, 3: ?}
Graph-motif information: No of triangles: 1| Triangles
attached to ? Node : [1,2,3]| ```
Image Modality
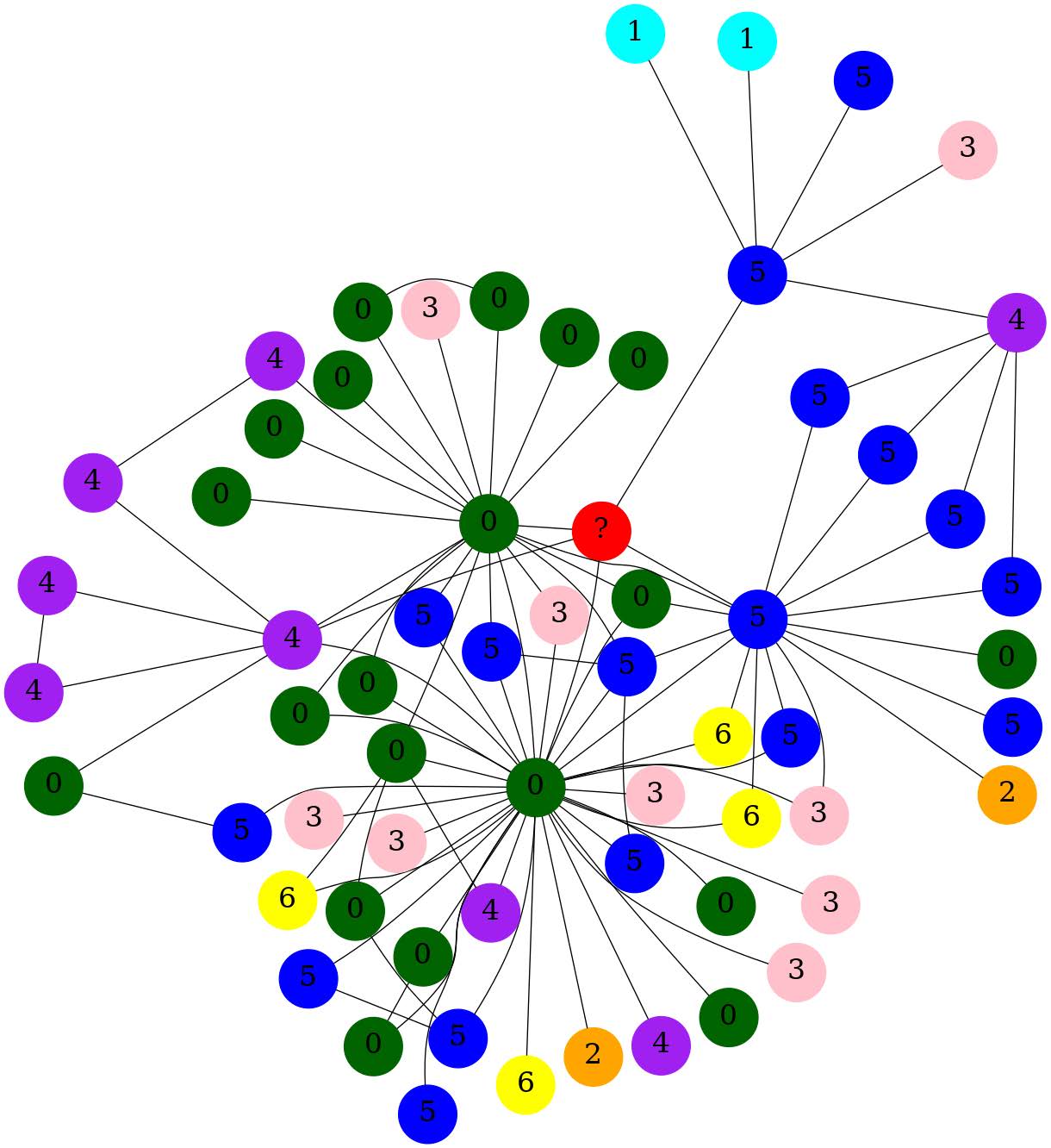
We first generate the graph rendering of our sampled graphs using NetworkX and color the nodes per the label values of each node.
We set the **unlabeled node always to be “red” and have a mark as a ‘?’ label on the node. **
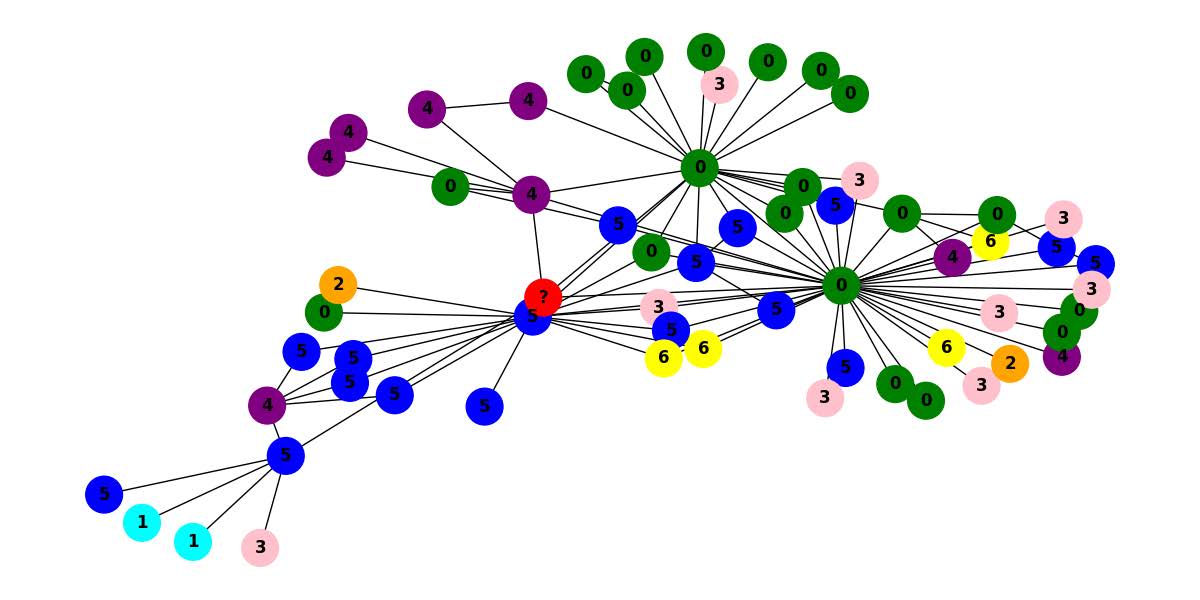
Image representation
How applying different changes to the image representation can enhance an image’s human readability. We then use these image encodings to evaluate the performance of node classification.
|
|
 |
 |
|---|---|---|
| Original NetworkX Graph | Node Size Increase 增加节点大小 |
Contrasting Text Color 这个子图对文本标签和节点颜色进行了对比,以提高标签的“人类可读性”。 |
 |
 |
 |
|---|---|---|
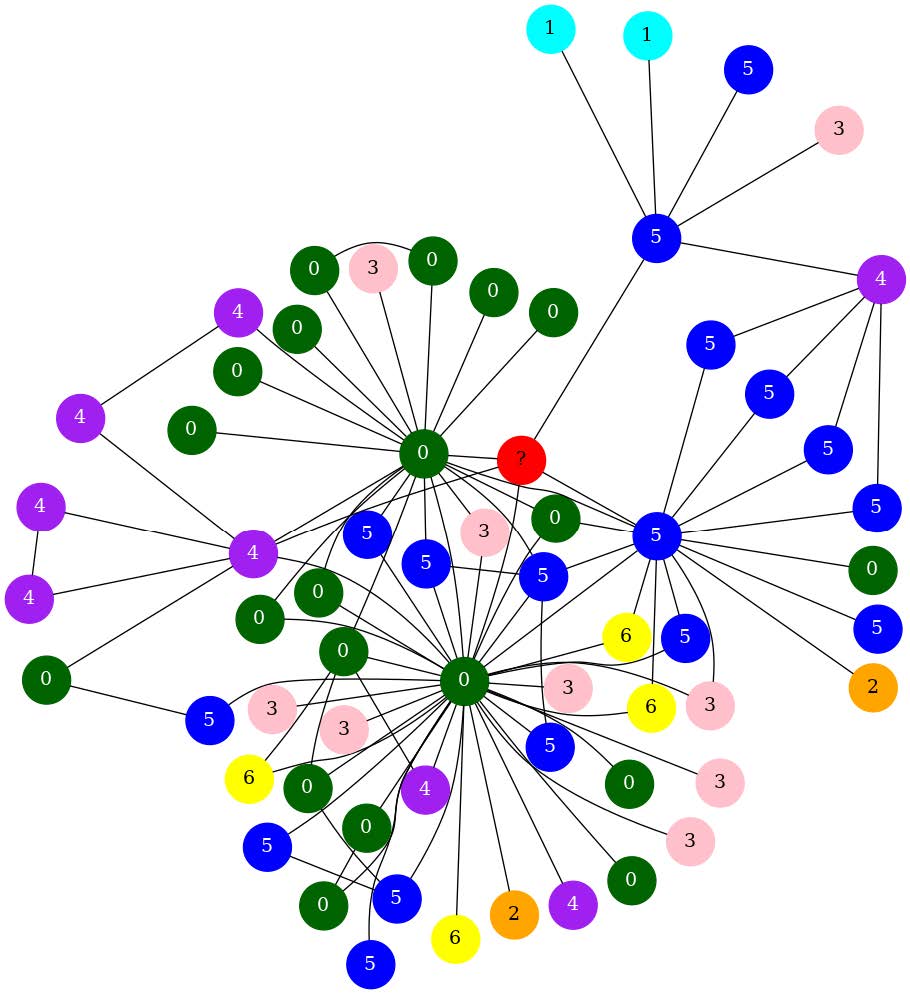
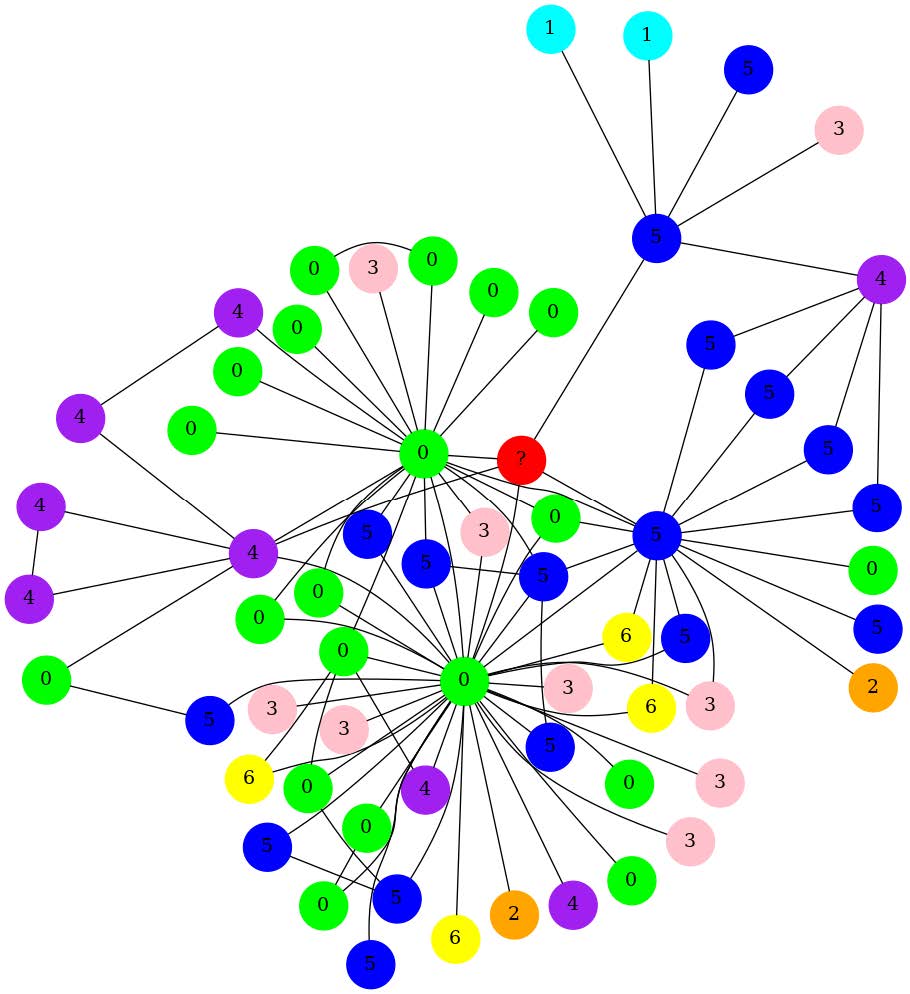
| Distinctive Node Colors 通过为不同标签的节点选择不同的颜色,可以更好地区分各个节点。 |
Node Size increase based on 1-Hop distance 增加了邻接节点的大小 |
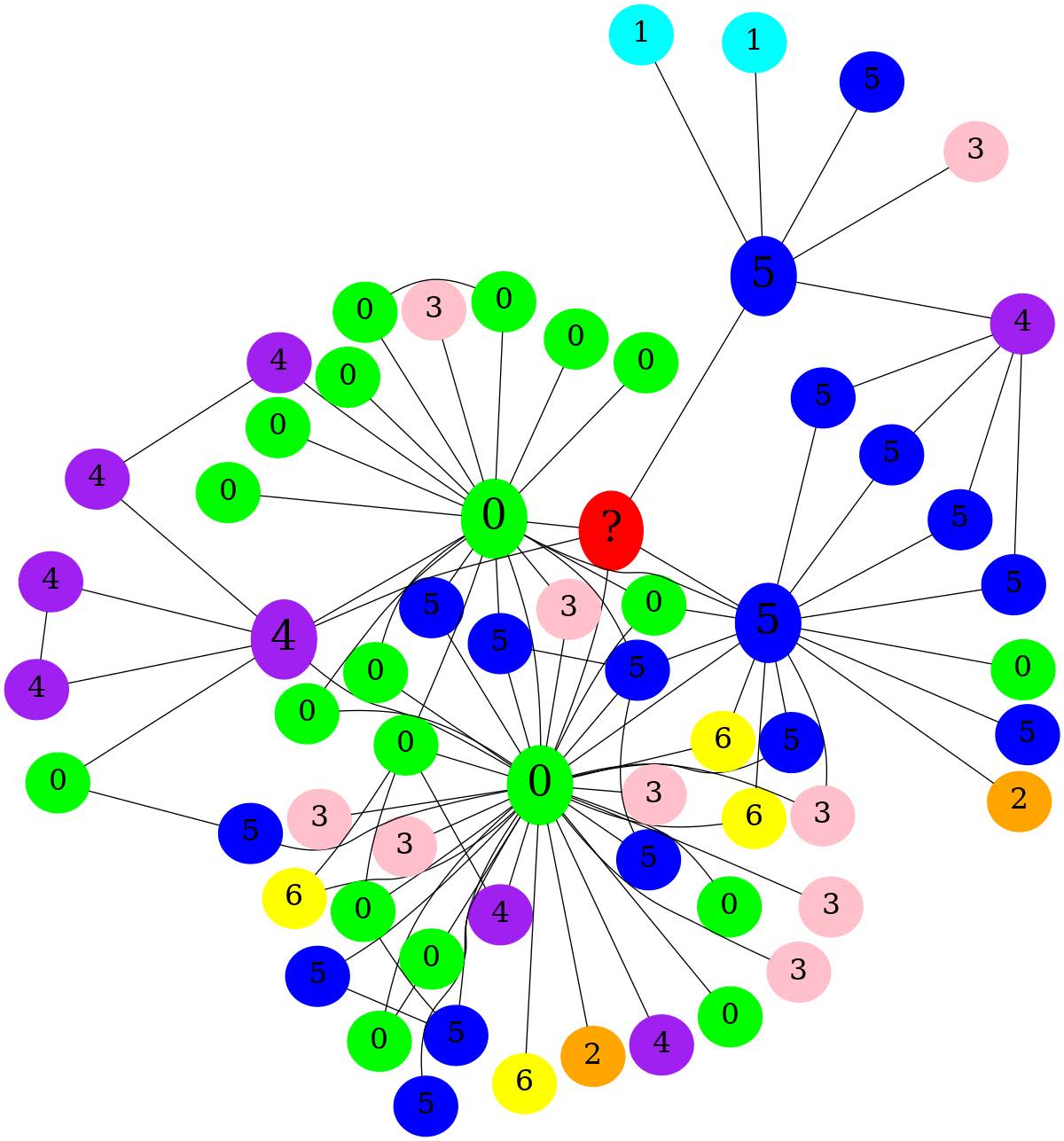
Aggregate all changes 应用上述所有优化方式 |
Result
Results Across All Modalities
| Cora | Citeseer | Pubmed | |
|---|---|---|---|
| GNN Baselines | |||
| GCN | 0.7584 ±0.121 | 0.6102 ±0.087 | 0.7546 ±0.076 |
| GAT | 0.7989 ±0.092 | 0.6583 ±0.074 | 0.7490 ±0.060 |
| GraphSage | 0.7719 ±0.124 | 0.6017 ±0.103 | 0.7193 ±0.076 |
| LLMs + Encoding Modality | |||
| Text🥇 | 0.81 ±0.04 [0.07 ±0.03] | 0.75 ±0.05 [0.07 ±0.01] | 0.83 ±0.01 [0.08 ±0.01]* |
| Motif | 0.73 ±0.06 [0.06 ±0.01] | 0.59 ±0.01 [0.32 ±0.02] | 0.77 ±0.06 [0.13 ±0.04] |
| Image🥈 | 0.77 ±0.05 [0.04 ±0.02]* | 0.71 ±0.09 [0.06 ±0.01]* | 0.79 ±0.03 [0.19 ±0.01] |
⭐From this table, we find that the text modality is comparable with graph baselines in all three datasets, while the image modality comes a close second. This shows the potential of LLMs to be a good foundational model for graphs.
⭐We also observe that **the lowest denial rate is for the image ** modality in the smaller CORA and Citeseer datasets, while the bigger Pubmed dataset shows a higher denial rate. This could be because of bigger subgraphs sampled, leading to congestion in the image modality, causing the LLM to deny a classification.
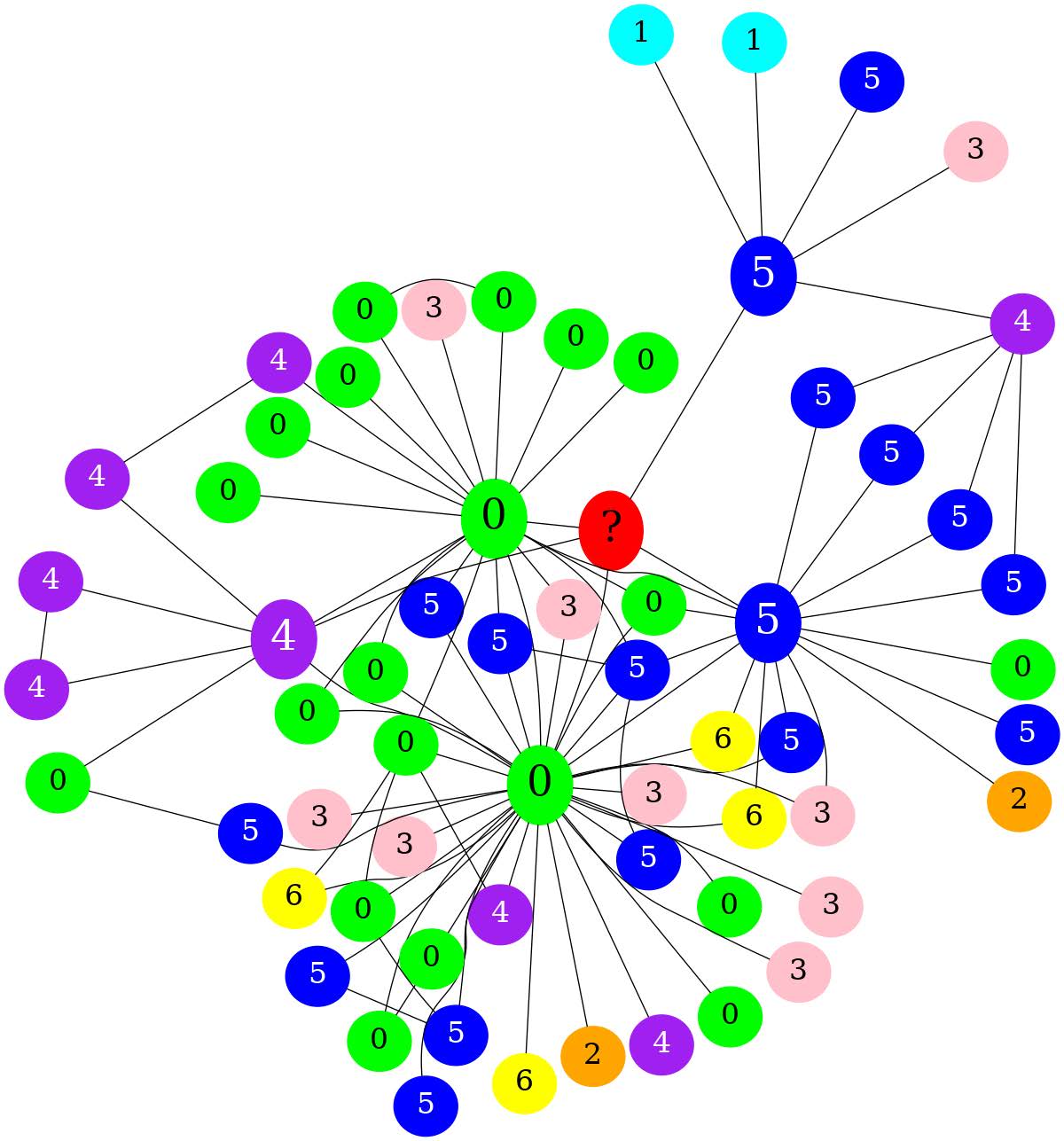
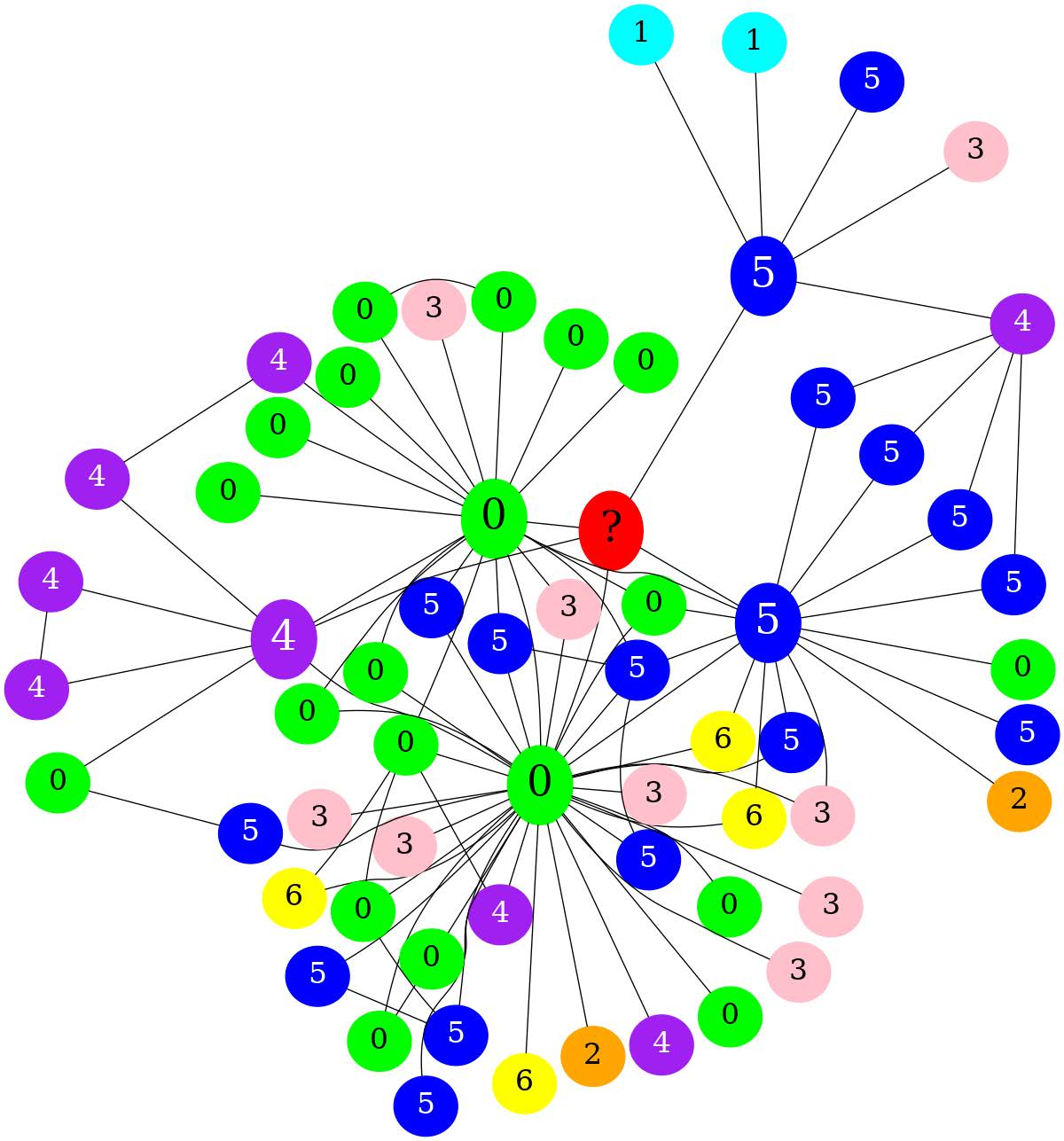
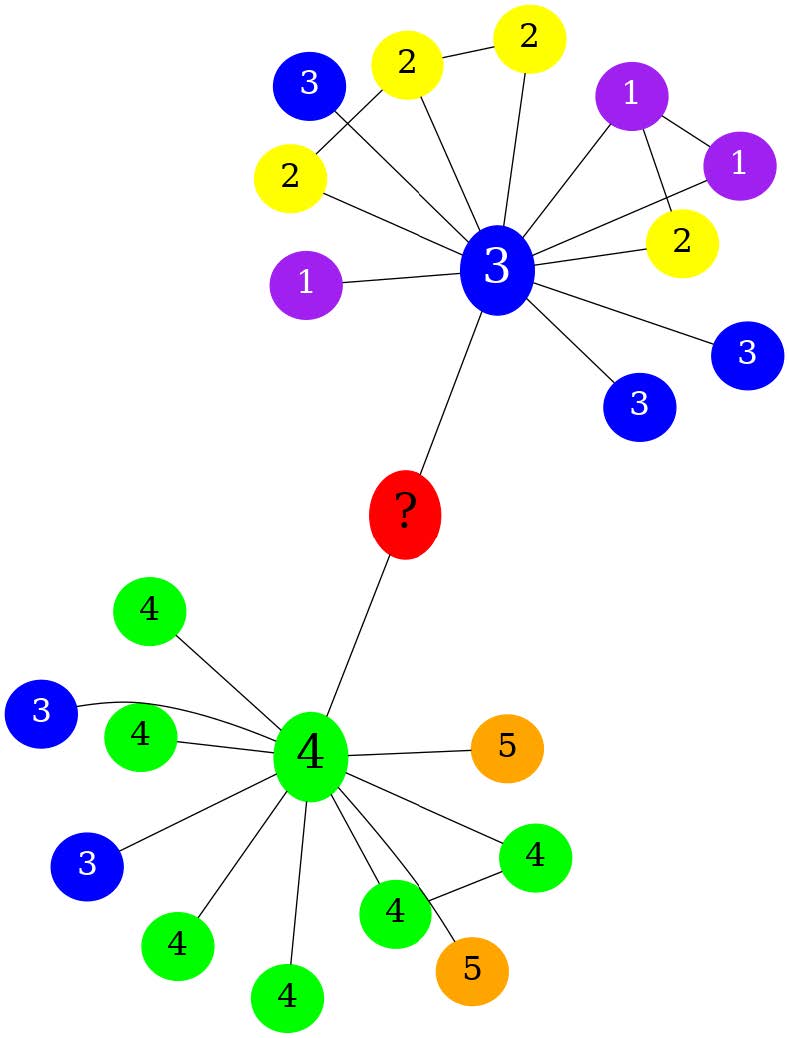
Qualitative analysis of denial of classification in the Image Modality
 |
 |
 |
|---|---|---|
| a.(Ground = 0) Without additional context or rules for how labels are assigned, it is not possible to accurately predict the label of the red node. 其他的节点都是按照label进行染色,然而?节点被染成了红色,这会使llm困惑。 |
b.(Ground = 4) The label cannot be determined with certainty due to the lack of a discernible pattern or rule that associates a node’s color or its connections with its label. 图中存在异质性 3-?-4 |
c.(Ground = 2) The label cannot be determined with certainty due to the lack of a clear pattern in the graph and no previous examples of red nodes to infer from. 需要few-shot |
We observe that a) the LLM requires context about how labels are assigned to each node. We left this information implicit in our image modality encoder, where every node is colored per its label. The red color is reserved for the ? node, which is unlabeled. This information is not explicit to the LLM. With image (b), there is no clear pattern associating the node’s color with its label, which is a confusion induced by the great amount of heterophily in the graph. Image (c) brings up the need for few-shot learning, This information is not explicit to the LLM given other graph examples.
Insights from GraphTMI
Easy problems (high homophily, simple graph structure) have higher accuracy with the image modality encoding. Graphs categorized as medium or hard, because of a heterophyllous nature or complex graph structure, have a higher accuracy with the text modality, though the image modality is not far behind.
Text Modality Results
Edge Encoding Function
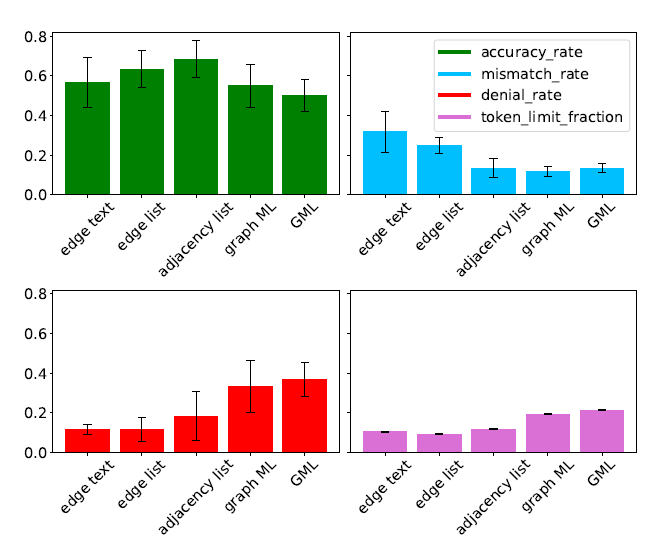
Figure shows that using the 🌟Adjacency List as the mode of edge representation with node label mapping is the most informative encoding function, which balances the trade-off between high accuracy and low token limit fraction
- accuracy rate(↑)
- mismatch rate (↓)
- denial rate (↓)
- token limit fraction (↓)
Impact of graph structure and graph sampling:
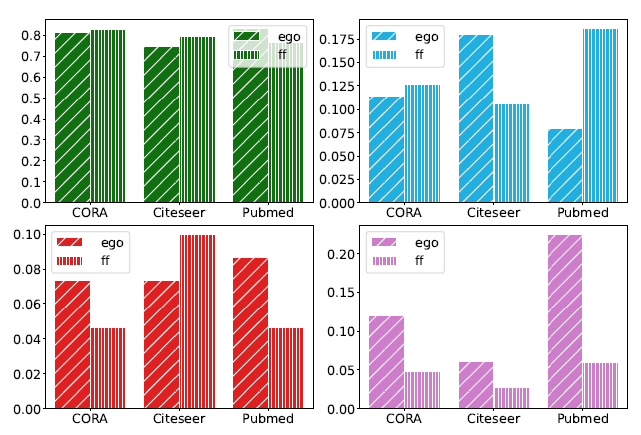
Green is the accuracy rate, Blue is the mismatch rate, Red is the denial rate, and Pink is the token limit fraction. The desired trends for each metric are given in brackets - (↑) accuracy rate, (↓) mismatch rate, (↓) denial rate, and (↓) token limit fraction. The x-axis distinguishes between ego graph sampling (ego) and forest fire sampling (ff) through different bar textures.
-
在准确率上影响不大,主要影响的是token limit fraction
-
两种采样方式在CORA上表现地都最好,可能因为它更小,更稠密,更聚集
Motif Modality Results
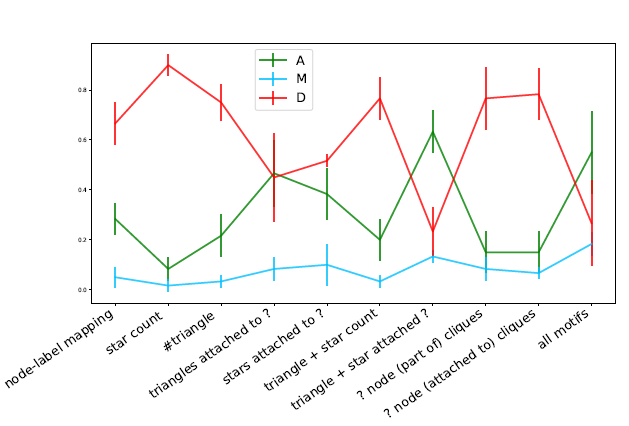
We observe that the mean accuracy rate goes up on adding the “triangle and star attached to ? node” motif, while the other metrics for the same setting are low.
- 此部分几乎没有进行分析,只提了“triangle and star attached to ? node” 最好,且一笔带过
Image Modality Results
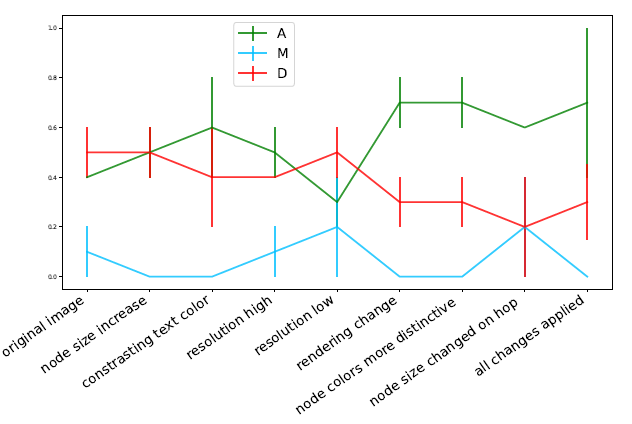
We observe that the “rendering change” offers the highest bump in accuracy, which only goes down when “node size is changed on hop”. This is probably because the LLM is confused bydifferent node sizes and their meaning. This could be resolved by clarifying the text prompt or using different shapes to represent nodes at different hop distances. Based on Figure 11, when “all the changes are applied”, the denial rate is minimum,and the accuracy rate is highest (0.7).
- 渲染变化确实能提高准确率
- 当“应用所有变化”时,拒绝率最低,准确率最高(0.7)
总结
- 使用image和motif模态来表示图作为llm的输入是之前没有看到过的
- 受限于算力和token limit,最大跳数被设置为了3